#computer audio system
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The most popular pages on Tumblr are about Minecraft, GIFs, and David J. Peterson.
Text
how well do Lando and Oscar know each other 2025 edition (with 2023 and 2024 callbacks)
fanstage video from l4ndocore on twt
#landoscar#mctwinks#twinklaren#mine#(SORRY tumblr messed up audio the first time)#considering I am digging these out of my computer by memory alone and I now have 2+ yrs worth of content#I rly need to cultivate a filing system @__@
257 notes
·
View notes
Text
if i hear another person talk about a retro game, system, or computer having a specific "soundfont" i think i'm gonna lose all will to live and spontaneously drop dead in front of them
#juney.txt#not how it works besties#older 8 bit machines generally had bespoke synthesizer chips that could output some square waves and some noise.#maybe some sine and saw waves if you were lucky#the megadrive had a yamaha chip in it but sega the bastards never gave devs proper instructions on how to use it#so a lotttt of devs just used the inbuilt settings on the development software they had#so a lot of megadrive games sound similar even though the system was technically capable of a lot more </3#the snes was allllll samples all day#any sounds you wanted you had to hand to the chip in advance#no inbuilt synths for you#anyway in all of these cases music data was just stored as raw computer instructions.#literally just code telling the audio hardware what to do each frame#no midis involved and simply slapping a soundfont someone made on a midi file someone else made does not constitute an ''8-bit'' cover
12 notes
·
View notes
Text
Man how I miss all of these...







#vinyl records#Video 8#Video8#Minidv#Mini dv#Vhs#Videotape#video tape#Videotapes#Video tapes#Video home system#Mp3 devices#Device#Music#Audio#Mp4#Reader#floppy disk#Disks#Vintage#Stuff#Old#Tech#Technology#Technologies#information technology#Computer#Cd#Dvd#compact disc
4 notes
·
View notes
Text
Francis Fan Lee, former professor and interdisciplinary speech processing inventor, dies at 96
New Post has been published on https://thedigitalinsider.com/francis-fan-lee-former-professor-and-interdisciplinary-speech-processing-inventor-dies-at-96/
Francis Fan Lee, former professor and interdisciplinary speech processing inventor, dies at 96

Francis Fan Lee ’50, SM ’51, PhD ’66, a former professor of MIT’s Department of Electrical Engineering and Computer Science, died on Jan. 12, some two weeks shy of his 97th birthday.
Born in 1927 in Nanjing, China, to professors Li Rumian and Zhou Huizhan, Lee learned English from his father, a faculty member in the Department of English at the University of Wuhan. Lee’s mastery of the language led to an interpreter position at the U.S. Office of Strategic Services, and eventually a passport and permission from the Chinese government to study in the United States.
Lee left China via steamship in 1948 to pursue his undergraduate education at MIT. He earned his bachelor’s and master’s degrees in electrical engineering in 1950 and 1951, respectively, before going into industry. Around this time, he became reacquainted with a friend he’d known in China, who had since emigrated; he married Teresa Jen Lee, and the two welcomed children Franklin, Elizabeth, Gloria, and Roberta over the next decade.
During his 10-year industrial career, Lee distinguished himself in roles at Ultrasonic (where he worked on instrument type servomechanisms, circuit design, and a missile simulator), RCA Camden (where he worked on an experimental time-shared digital processor for department store point-of-sale interactions), and UNIVAC Corp. (where he held a variety of roles, culminating in a stint in Philadelphia, planning next-generation computing systems.)
Lee returned to MIT to earn his PhD in 1966, after which he joined the then-Department of Electrical Engineering as an associate professor with tenure, affiliated with the Research Laboratory of Electronics (RLE). There, he pursued the subject of his doctoral research: the development of a machine that would read printed text out loud — a tremendously ambitious and complex goal for the time.
Work on the “RLE reading machine,” as it was called, was inherently interdisciplinary, and Lee drew upon the influences of multiple contemporaries, including linguists Morris Halle and Noam Chomsky, and engineer Kenneth Stevens, whose quantal theory of speech production and recognition broke down human speech into discrete, and limited, combinations of sound. One of Lee’s greatest contributions to the machine, which he co-built with Donald Troxel, was a clever and efficient storage system that used root words, prefixes, and suffixes to make the real-time synthesis of half-a-million English words possible, while only requiring about 32,000 words’ worth of storage. The solution was emblematic of Lee’s creative approach to solving complex research problems, an approach which earned him respect and admiration from his colleagues and contemporaries.
In reflection of Lee’s remarkable accomplishments in both industry and building the reading machine, he was promoted to full professor in 1969, just three years after he earned his PhD. Many awards and other recognition followed, including the IEEE Fellowship in 1971 and the Audio Engineering Society Best Paper Award in 1972. Additionally, Lee occupied several important roles within the department, including over a decade spent as the undergraduate advisor. He consistently supported and advocated for more funding to go to ongoing professional education for faculty members, especially those who were no longer junior faculty, identifying ongoing development as an important, but often-overlooked, priority.
Lee’s research work continued to straddle both novel inquiry and practical, commercial application — in 1969, together with Charles Bagnaschi, he founded American Data Sciences, later changing the company’s name to Lexicon Inc. The company specialized in producing devices that expanded on Lee’s work in digital signal compression and expansion: for example, the first commercially available speech compressor and pitch shifter, which was marketed as an educational tool for blind students and those with speech processing disorders. The device, called Varispeech, allowed students to speed up written material without losing pitch — much as modern audiobook listeners speed up their chapters to absorb books at their preferred rate. Later innovations of Lee’s included the Time Compressor Model 1200, which added a film and video component to the speeding-up process, allowing television producers to subtly speed up a movie, sitcom, or advertisement to precisely fill a limited time slot without having to resort to making cuts. For this work, he received an Emmy Award for technical contributions to editing.
In the mid-to-late 1980s, Lee’s influential academic career was brought to a close by a series of deeply personal tragedies, including the 1984 murder of his daughter Roberta, and the subsequent and sudden deaths of his wife, Theresa, and his son, Franklin. Reeling from his losses, Lee ultimately decided to take an early retirement, dedicating his energy to healing. For the next two decades, he would explore the world extensively, a nomadic second chapter that included multiple road trips across the United States in a Volkswagen camper van. He eventually settled in California, where he met his last wife, Ellen, and where his lively intellectual life persisted despite diagnoses of deafness and dementia; as his family recalled, he enjoyed playing games of Scrabble until his final weeks.
He is survived by his wife Ellen Li; his daughters Elizabeth Lee (David Goya) and Gloria Lee (Matthew Lynaugh); his grandsons Alex, Benjamin, Mason, and Sam; his sister Li Zhong (Lei Tongshen); and family friend Angelique Agbigay. His family have asked that gifts honoring Francis Fan Lee’s life be directed to the Hertz Foundation.
#000#1980s#Alumni/ae#approach#audio#birthday#Books#Born#Building#career#Children#China#compression#compressor#computer#Computer Science#computing#computing systems#data#dementia#Design#development#devices#disorders#Editing#education#Electrical Engineering&Computer Science (eecs)#Electronics#energy#Engineer
2 notes
·
View notes
Video
Computer Speakers. #computerspeakers #audio #pc
2 notes
·
View notes
Text
lmao
'People are panicking about AI tools the same way they did when the calculator was invented, stop worrying' cannot stress enough the calculator did not forcibly pervade every aspect of our lives, has such a low error rate it's a statistical anomaly when it does happen, isn't built on mass plagiarism, and does not obliterate the fucking environment when you use it. Be so fucking serious right now
#do you realize how stupid you'd end up becoming by using AI?#1. you wouldnt be able to handle constructive crit#2. You'd lose your meaning of life#Creating is FUN. Its supposed to be FUN. Its one of the few things you look forward to after a long day of work#And what? You want to take ideas from a machine that will take the art pattern most commonly found and copy THAT?#WHERES YOUR ORIGINALITY MAN#calculators are fine. They only replaced quick math calc skills#Audio recorders are fine. They made shorthand obsolete#Computers are WAY fine. I can now talk to my mutuals and friends online that are def on the opposite sides of the world#But AI?#really?#The random knucklehead of a machine that spouts your essay for you while you do other things?#YOU WOULDNT EVEN LEARN TIME MANAGEMENT#OR HOW TO PRIORITISE#OR WHAT ON EARTH MATTERS THE MOST TO YOU#urgh screw AI#No one wants to pay people cuz broke#If everyone wants free stuff and its all cuz capitalusm#Doesnt allow you to#Then maybe we should go back to the barter system just sayin
107K notes
·
View notes
Text
Brennan when D20 first started: Yeah, we're in a dome that can change colors depending on the situation, blue to start out, red for combat, we've got some purple and some green and maybe some yellow in there for ambiance, custom battle sets made by Rick Perry :)
Brennan for Crown of Candy: Okay... hear me out... more than one color at a time on the dome
*Insert about a year of doing seasons online due to quarantine*
Aabria, rocking up for MisMag: Hmm... new system :) Custom props :) Background effects for dome :)
Brennan, eye twitching slightly: Okay... what about strobing light effects on the dome? What about custom computers for the digital battlesets?
Aabria, grinning evilly: What about flowers all over the dome? What about in-theme makeup looks? What about physical props for moments that happen organically in the campaign? What about ambient lighting? WHAT ABOUT BACKGROUND PROJECTIONS?
Brennan, slamming hands on the table: BACKGROUND PROJECTIONS?! HOW ABOUT BACKGROUND ANIMATIONS, BABY?! HOW ABOUT MOVING SET PIECES THAT COME IN FROM THE CEILING?! YOU DRESS UP ALL THE TIME? WELL, I'M DRESSING UP FOR OUR DRAG QUEEN SEASON! AND I'M NOT DONE, I GOT A WHOLE NEW NOIR-THEMED SIDEQUEST! I'M MAKING THAT OTHER GAME-SYSTEM NOIR THEMED AND BRINGING IN NOIR LIGHTING AND MAKING TRACKS FOR THOSE TOKENS TO ROLL DOWN IN AND ANIMATED SCENES TO PROJECT ONTO THE DOME!
Aabria, floating into the air Galadriel-style: PUZZLE BATTLESETS! ANTI-SURVEILLANCE MAKEUP! I GOT CARLOS LUNA TO RECORD WHOLE-ASS AUDIO LOG ENTRIES FOR YOU GUYS TO DISCOVER AS YOU UNRAVEL THIS MYSTERY!
Brennan, going Super Saiyan: MINIS FOR EVERY GODDAMN OCCASION! EVERY SINGLE BATTLESET IS MORE ELABORATE THAN THE LAST! I GOT WORDS ON THE DOME! I'M INCLUDING A PLOT-IMPORTANT CLIP FROM FIVE FUCKING YEARS AGO TO PROJECT! I GOT SMOKE EFFECTS AND EXPLOSION EFFECTS! MY DM COSTUME GETS MORE AND MORE ACTION-MOVIE RUGGED AS THE SHOW GOES ON! I MADE A WHOLE! NEW! SYSTEM!
Aabria, achieving godhood: THE SET MOVES! THERE ARE WIND EFFECTS! I TOOK YOUR NEW SYSTEM AND I MADE A MAGIC VERSION! I GOT HOLOGRAMS IN THE DOME, BITCH! CARLOS LUNA IS RIGHT BACKSTAGE WITH A MOTION-CAP THING ATTACHED TO HIS FACE AS HE DELIVERS LINES FOR THE TALKING ROCK!
Brennan, achieving elder godhood: FLAMETHROWERS FOR THE LIVESHOW IN NEW YORK! THE GIANT MONSTERS ARE REMOTE-CONTROLLED! THE DRAGON ACTUALLY BREATHES OUT SMOKE! AND I GOT GLOW-IN-THE-DARK BLACKLIGHT MAKEUP EFFECTS! ME, THE GUY WHO ALWAYS WEARS THE SAME FIVE SHIRTS!
(@quiddie please confirm that this is how the production conversation goes between you and Brennan)
#they're just constantly building off of what the other has done before#and it's both out of respect and out of a healthy competition#i'm still kind of in awe that brennan got to the glow-in-the-dark makeup BEFORE AABRIA#dimension 20#brennan lee mulligan#aabria iyengar
6K notes
·
View notes
Text
The Future of Consumer Electronics: Market Insights and Forecast
Stay ahead in the ever-evolving consumer electronics market. Explore the latest trends, growth opportunities, and innovative technologies shaping the industry. Be a part of the future of electronics.
#Audio Systems market#Home theater audio market trends#Bluetooth speaker market Size#Wireless audio device market#consumer electronics market#consumer electronics market share#drone camera market#Desktop Computers market#Laptop market size#computer accessories market#smart kitchen appliances market#Microwaves oven market#global air conditioner market#vacuum cleaners market#Lighting industry size#mobile phone market size#smartphone market size
1 note
·
View note
Text
Kickstarting a book to end enshittification, because Amazon will not carry it

My next book is The Internet Con: How to Seize the Means of Computation: it’s a Big Tech disassembly manual that explains how to disenshittify the web and bring back the old good internet. The hardcover comes from Verso on Sept 5, but the audiobook comes from me — because Amazon refuses to sell my audio:
https://www.kickstarter.com/projects/doctorow/the-internet-con-how-to-seize-the-means-of-computation
Amazon owns Audible, the monopoly audiobook platform that controls >90% of the audio market. They require mandatory DRM for every book sold, locking those books forever to Amazon’s monopoly platform. If you break up with Amazon, you have to throw away your entire audiobook library.
That’s a hell of a lot of leverage to hand to any company, let alone a rapacious monopoly that ran a program targeting small publishers called “Project Gazelle,” where execs were ordered to attack indie publishers “the way a cheetah would pursue a sickly gazelle”:
https://www.businessinsider.com/sadistic-amazon-treated-book-sellers-the-way-a-cheetah-would-pursue-a-sickly-gazelle-2013-10

[Image ID: Journalist and novelist Doctorow (Red Team Blues) details a plan for how to break up Big Tech in this impassioned and perceptive manifesto….Doctorow’s sense of urgency is contagious -Publishers Weekly]
I won’t sell my work with DRM, because DRM is key to the enshittification of the internet. Enshittification is why the old, good internet died and became “five giant websites filled with screenshots of the other four” (h/t Tom Eastman). When a tech company can lock in its users and suppliers, it can drain value from both sides, using DRM and other lock-in gimmicks to keep their business even as they grow ever more miserable on the platform.
Here is how platforms die: first, they are good to their users; then they abuse their users to make things better for their business customers; finally, they abuse those business customers to claw back all the value for themselves. Then, they die:
https://pluralistic.net/2023/01/21/potemkin-ai/#hey-guys

[Image ID: A brilliant barn burner of a book. Cory is one of the sharpest tech critics, and he shows with fierce clarity how our computational future could be otherwise -Kate Crawford, author of The Atlas of AI”]
The Internet Con isn’t just an analysis of where enshittification comes from: it’s a detailed, shovel-ready policy prescription for halting enshittification, throwing it into reverse and bringing back the old, good internet.
How do we do that? With interoperability: the ability to plug new technology into those crapulent, decaying platform. Interop lets you choose which parts of the service you want and block the parts you don’t (think of how an adblocker lets you take the take-it-or-leave “offer” from a website and reply with “How about nah?”):
https://www.eff.org/deeplinks/2019/07/adblocking-how-about-nah
But interop isn’t just about making platforms less terrible — it’s an explosive charge that demolishes walled gardens. With interop, you can leave a social media service, but keep talking to the people who stay. With interop, you can leave your mobile platform, but bring your apps and media with you to a rival’s service. With interop, you can break up with Amazon, and still keep your audiobooks.
So, if interop is so great, why isn’t it everywhere?
Well, it used to be. Interop is how Microsoft became the dominant operating system:
https://www.eff.org/deeplinks/2019/06/adversarial-interoperability-reviving-elegant-weapon-more-civilized-age-slay

[Image ID: Nobody gets the internet-both the nuts and bolts that make it hum and the laws that shaped it into the mess it is-quite like Cory, and no one’s better qualified to deliver us a user manual for fixing it. That’s The Internet Con: a rousing, imaginative, and accessible treatise for correcting our curdled online world. If you care about the internet, get ready to dedicate yourself to making interoperability a reality. -Brian Merchant, author of Blood in the Machine]
It’s how Apple saved itself from Microsoft’s vicious campaign to destroy it:
https://www.eff.org/deeplinks/2019/06/adversarial-interoperability-reviving-elegant-weapon-more-civilized-age-slay
Every tech giant used interop to grow, and then every tech giant promptly turned around and attacked interoperators. Every pirate wants to be an admiral. When Big Tech did it, that was progress; when you do it back to Big Tech, that’s piracy. The tech giants used their monopoly power to make interop without permission illegal, creating a kind of “felony contempt of business model” (h/t Jay Freeman).
The Internet Con describes how this came to pass, but, more importantly, it tells us how to fix it. It lays out how we can combine different kinds of interop requirements (like the EU’s Digital Markets Act and Massachusetts’s Right to Repair law) with protections for reverse-engineering and other guerrilla tactics to create a system that is strong without being brittle, hard to cheat on and easy to enforce.
What’s more, this book explains how to get these policies: what existing legislative, regulatory and judicial powers can be invoked to make them a reality. Because we are living through the Great Enshittification, and crises erupt every ten seconds, and when those crises occur, the “good ideas lying around” can move from the fringes to the center in an eyeblink:
https://pluralistic.net/2023/06/12/only-a-crisis/#lets-gooooo

[Image ID: Thoughtfully written and patiently presented, The Internet Con explains how the promise of a free and open internet was lost to predatory business practices and the rush to commodify every aspect of our lives. An essential read for anyone that wants to understand how we lost control of our digital spaces and infrastructure to Silicon Valley’s tech giants, and how we can start fighting to get it back. -Tim Maughan, author of INFINITE DETAIL]
After all, we’ve known Big Tech was rotten for years, but we had no idea what to do about it. Every time a Big Tech colossus did something ghastly to millions or billions of people, we tried to fix the tech company. There’s no fixing the tech companies. They need to burn. The way to make users safe from Big Tech predators isn’t to make those predators behave better — it’s to evacuate those users:
https://pluralistic.net/2023/07/18/urban-wildlife-interface/#combustible-walled-gardens
I’ve been campaigning for human rights in the digital world for more than 20 years; I’ve been EFF’s European Director, representing the public interest at the EU, the UN, Westminster, Ottawa and DC. This is the subject I’ve devoted my life to, and I live my principles. I won’t let my books be sold with DRM, which means that Audible won’t carry my audiobooks. My agent tells me that this decision has cost me enough money to pay off my mortgage and put my kid through college. That’s a price I’m willing to pay if it means that my books aren’t enshittification bait.
But not selling on Audible has another cost, one that’s more important to me: a lot of readers prefer audiobooks and 9 out of 10 of those readers start and end their searches on Audible. When they don’t find an author there, they assume no audiobook exists, period. It got so bad I put up an audiobook on Amazon — me, reading an essay, explaining how Audible rips off writers and readers. It’s called “Why None of My Audiobooks Are For Sale on Audible”:
https://pluralistic.net/2022/07/25/can-you-hear-me-now/#acx-ripoff

[Image ID: Doctorow has been thinking longer and smarter than anyone else I know about how we create and exchange value in a digital age. -Douglas Rushkoff, author of Present Shock]
To get my audiobooks into readers’ ears, I pre-sell them on Kickstarter. This has been wildly successful, both financially and as a means of getting other prominent authors to break up with Amazon and use crowdfunding to fill the gap. Writers like Brandon Sanderson are doing heroic work, smashing Amazon’s monopoly:
https://www.brandonsanderson.com/guest-editorial-cory-doctorow-is-a-bestselling-author-but-audible-wont-carry-his-audiobooks/
And to be frank, I love audiobooks, too. I swim every day as physio for a chronic pain condition, and I listen to 2–3 books/month on my underwater MP3 player, disappearing into an imaginary world as I scull back and forth in my public pool. I’m able to get those audiobooks on my MP3 player thanks to Libro.fm, a DRM-free store that supports indie booksellers all over the world:
https://blog.libro.fm/a-qa-with-mark-pearson-libro-fm-ceo-and-co-founder/
Producing my own audiobooks has been a dream. Working with Skyboat Media, I’ve gotten narrators like @wilwheaton, Amber Benson, @neil-gaiman and Stefan Rudnicki for my work:
https://craphound.com/shop/

[Image ID: “This book is the instruction manual Big Tech doesn’t want you to read. It deconstructs their crummy products, undemocratic business models, rigged legal regimes, and lies. Crack this book and help build something better. -Astra Taylor, author of Democracy May Not Exist, but We’ll Miss It When Its Gone”]
But for this title, I decided that I would read it myself. After all, I’ve been podcasting since 2006, reading my own work aloud every week or so, even as I traveled the world and gave thousands of speeches about the subject of this book. I was excited (and a little trepedatious) at the prospect, but how could I pass up a chance to work with director Gabrielle de Cuir, who has directed everyone from Anne Hathaway to LeVar Burton to Eric Idle?
Reader, I fucking nailed it. I went back to those daily recordings fully prepared to hate them, but they were good — even great (especially after my engineer John Taylor Williams mastered them). Listen for yourself!
https://archive.org/details/cory_doctorow_internet_con_chapter_01
I hope you’ll consider backing this Kickstarter. If you’ve ever read my free, open access, CC-licensed blog posts and novels, or listened to my podcasts, or come to one of my talks and wished there was a way to say thank you, this is it. These crowdfunders make my DRM-free publishing program viable, even as audiobooks grow more central to a writer’s income and even as a single company takes over nearly the entire audiobook market.
Backers can choose from the DRM-free audiobook, DRM-free ebook (EPUB and MOBI) and a hardcover — including a signed, personalized option, fulfilled through the great LA indie bookstore Book Soup:
https://www.kickstarter.com/projects/doctorow/the-internet-con-how-to-seize-the-means-of-computation
What’s more, these ebooks and audiobooks are unlike any you’ll get anywhere else because they are sold without any terms of service or license agreements. As has been the case since time immemorial, when you buy these books, they’re yours, and you are allowed to do anything with them that copyright law permits — give them away, lend them to friends, or simply read them with any technology you choose.
As with my previous Kickstarters, backers can get their audiobooks delivered with an app (from libro.fm) or as a folder of MP3s. That helps people who struggle with “sideloading,” a process that Apple and Google have made progressively harder, even as they force audiobook and ebook sellers to hand over a 30% app tax on every dollar they make:
https://www.kickstarter.com/projects/doctorow/red-team-blues-another-audiobook-that-amazon-wont-sell/posts/3788112
Enshittification is rotting every layer of the tech stack: mobile, payments, hosting, social, delivery, playback. Every tech company is pulling the rug out from under us, using the chokepoints they built between audiences and speakers, artists and fans, to pick all of our pockets.
The Internet Con isn’t just a lament for the internet we lost — it’s a plan to get it back. I hope you’ll get a copy and share it with the people you love, even as the tech platforms choke off your communities to pad their quarterly numbers.

Next weekend (Aug 4-6), I'll be in Austin for Armadillocon, a science fiction convention, where I'm the Guest of Honor:
https://armadillocon.org/d45/
If you'd like an essay-formatted version of this thread to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/07/31/seize-the-means-of-computation/#the-internet-con
[Image ID: My forthcoming book 'The Internet Con: How to Seize the Means of Computation' in various editions: Verso hardcover, audiobook displayed on a phone, and ebook displayed on an e-ink reader.]
#pluralistic#trustbusting#big tech#gift guide#kickstarter#the internet con#books#audiobooks#enshitiffication#disenshittification#crowdfunders#seize the means of computation#audible#amazon#verso
15K notes
·
View notes
Text
I’m Declaring War Against “What If” Videos: Project Copy-Knight

What Are “What If” Videos?
These videos follow a common recipe: A narrator, given a fandom (usually anime ones like My Hero Academia and Naruto), explores an alternative timeline where something is different. Maybe the main character has extra powers, maybe a key plot point goes differently. They then go on and make up a whole new story, detailing the conflicts and romance between characters, much like an ordinary fanfic.
Except, they are fanfics. Actual fanfics, pulled off AO3, FFN and Wattpad, given a different title, with random thumbnail and background images added to them, narrated by computer text-to-speech synthesizers.
They are very easy to make: pick a fanfic, copy all the text into a text-to-speech generator, mix the resulting audio file with some generic art from the fandom as the background, give it a snappy title like “What if Deku had the Power of Ten Rings”, photoshop an attention-grabbing thumbnail, dump it onto YouTube and get thousands of views.
In fact, the process is so straightforward and requires so little effort, it’s pretty clear some of these channels have automated pipelines to pump these out en-masse. They don’t bother with asking the fic authors for permission. Sometimes they don’t even bother with putting the fic’s link in the description or crediting the author. These content-farms then monetise these videos, so they get a cut from YouTube’s ads.
In short, an industry has emerged from the systematic copyright theft of fanfiction, for profit.
Project Copy-Knight
Since the adversaries almost certainly have automated systems set up for this, the only realistic countermeasure is with another automated system. Identifying fanfics manually by listening to the videos and searching them up with tags is just too slow and impractical.
And so, I came up with a simple automated pipeline to identify the original authors of “What If” videos.
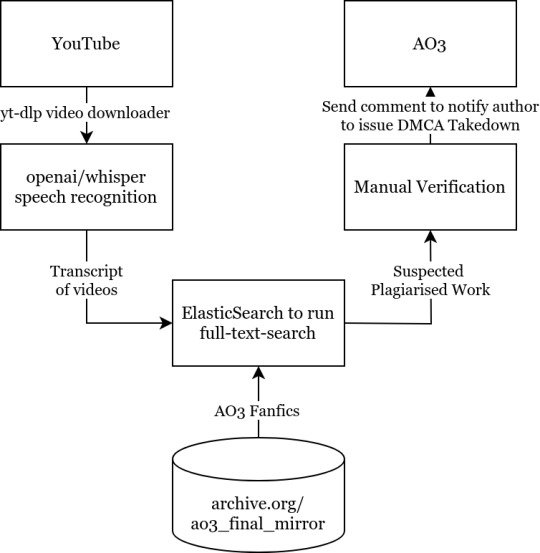
It would go download these videos, run speech recognition on it, search the text through a database full of AO3 fics, and identify which work it came from. After manual confirmation, the original authors will be notified that their works have been subject to copyright theft, and instructions provided on how to DMCA-strike the channel out of existence.
I built a prototype over the weekend, and it works surprisingly well:
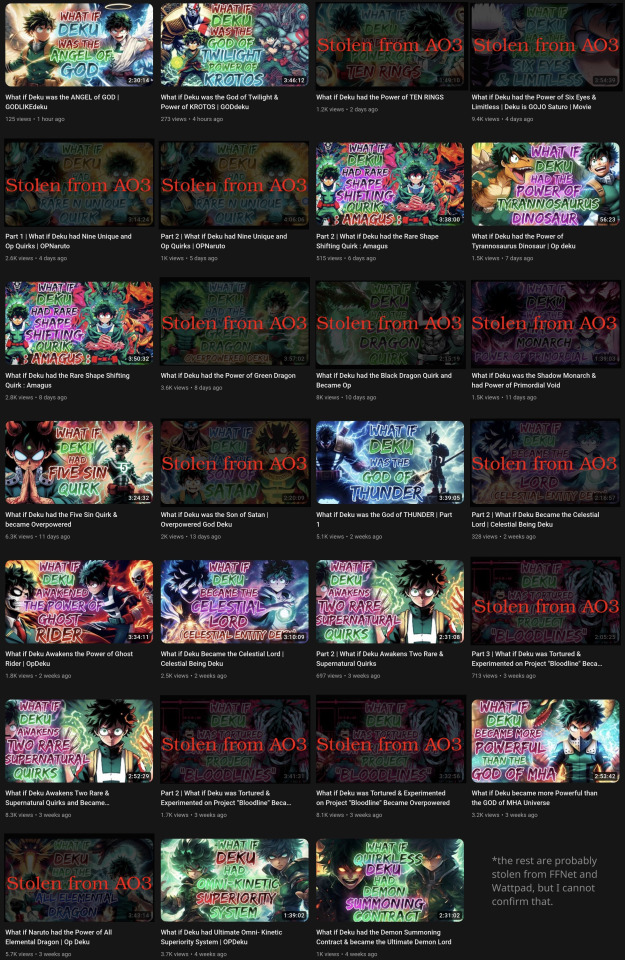
On a randomly-selected YouTube channel (in this case Infinite Paradox Fanfic), the toolchain was able to identify the origin of half of the content. The raw output, after manual verification, turned out to be extremely accurate. The time taken to identify the source of a video was about 5 minutes, most of those were spent running Whisper, and the actual full-text-search query and Levenshtein analysis was less than 5 seconds.
The other videos probably came from fanfiction websites other than AO3, like fanfiction.net or Wattpad. As I do not have access to archives of those websites, I cannot identify the other ones, but they are almost certainly not original.
Armed with this fantastic proof-of-concept, I’m officially declaring war against “What If” videos. The mission statement of Project Copy-Knight will be the elimination of “What If” videos based on the theft of AO3 content on YouTube.
I Need Your Help
I am acutely aware that I cannot accomplish this on my own. There are many moving parts in this system that simply cannot be completely automated – like the selection of YouTube channels to feed into the toolchain, the manual verification step to prevent false-positives being sent to authors, the reaching-out to authors who have comments disabled, etc, etc.
So, if you are interested in helping to defend fanworks, or just want to have a chat or ask about the technical details of the toolchain, please consider joining my Discord server. I could really use your help.
------
See full blog article and acknowledgements here: https://echoekhi.com/2023/11/25/project-copy-knight/
7K notes
·
View notes
Text
I have been trying to rip a concert recording from a streaming site for 2 DAYS now and it has not been successful and I am SO CLOSE TO ENDING IT
#i tried to get obs to work for hours before I read on a random tutorial that it simply doesn’t allow system audio recording on mac#i have never worked this hard on a project on the computer i hate tech stuff but I neeeeeed this recording
0 notes
Text
words for users !
ideias de palavras aleatórias para ajudar você a criar seu próprio user;
random ideas of words to help you to create your own user.

core -> aesthetic core
vlog -> daily videos
logs -> daily facts
mp3 -> audio file format
m4p -> apple audio file format
mp4 -> video file format
txt -> text format
jpeg -> image file format
jpg -> image file format
png -> image file format
gif -> animated file format
raw -> uncompressed file format
zip -> compressed archive file format
rar -> compressed archive file format
web -> internet file format
doc -> document file
pdf -> document file
vinyl -> phonograph record
film -> motion picture; photography
user -> person who utilizes a computer or network service
i2 -> "keeping it real"
self -> a person's essential being
itself -> a person's essential being
priv -> private
luv -> love's short form
tale -> a fictitious or true narrative or story
archive -> to place or store (something) in an archive
list -> connected items
tier -> a type of hierarchy
talk -> speak in order to express something
chat -> to have a conversation
post -> to announce or publish something
zone -> a subject to particular restrictions
vie -> life in french
tie -> to form a knot or bow in
on/online -> connected to a network
byte -> a group of binary digits
bits -> a small piece, part, or quantity of something
ram -> hardware in a computing device
8bit -> computer term used to designate either color depth
pixel -> a minute area of illumination on a display screen
data -> things known or assumed as facts
series -> a number of things, events, or people of a similar kind
village -> a self-contained community within a town or city
lab -> a laboratory
lady -> a woman
miss -> a form of address to a woman
mister -> a form of address to a man
error -> something not found
art -> the various branches of creative activity
petit -> small in french
poet -> a person possessing special powers of imagination or expression
thing -> an object without a specific name
stuff -> a vague reference to additional things
vogue -> the prevailing fashion or style at a particular time
tv -> taylor's version and/or television as a system or form of media
media -> the main means of mass communication
topia -> an imagined place or state of things in which everything is perfect
saur -> forming names of extinct reptiles such as dinosaurs
tune -> a melody, one that characterizes a particular piece of music
deun -> melody in deutsch
off/offline -> disconnected from the Internet
gloss -> shine or luster on a smooth surface
fae -> a fairy, in modern fantasy fiction
#random users#cute usernames#tumblr users#twitter users#usernames#user ideas#aesthetic usernames#soft users#users#aesthetic url#messycore#messy aesthetic#alt aesthetic#messy packs#aesthetic core#user#user name#random#random user ideas#random user#random ideas#text post#masterpost#masterlist#long post#long list
4K notes
·
View notes
Text
Anthropic's stated "AI timelines" seem wildly aggressive to me.
As far as I can tell, they are now saying that by 2028 – and possibly even by 2027, or late 2026 – something they call "powerful AI" will exist.
And by "powerful AI," they mean... this (source, emphasis mine):
In terms of pure intelligence, it is smarter than a Nobel Prize winner across most relevant fields – biology, programming, math, engineering, writing, etc. This means it can prove unsolved mathematical theorems, write extremely good novels, write difficult codebases from scratch, etc. In addition to just being a “smart thing you talk to”, it has all the “interfaces” available to a human working virtually, including text, audio, video, mouse and keyboard control, and internet access. It can engage in any actions, communications, or remote operations enabled by this interface, including taking actions on the internet, taking or giving directions to humans, ordering materials, directing experiments, watching videos, making videos, and so on. It does all of these tasks with, again, a skill exceeding that of the most capable humans in the world. It does not just passively answer questions; instead, it can be given tasks that take hours, days, or weeks to complete, and then goes off and does those tasks autonomously, in the way a smart employee would, asking for clarification as necessary. It does not have a physical embodiment (other than living on a computer screen), but it can control existing physical tools, robots, or laboratory equipment through a computer; in theory it could even design robots or equipment for itself to use. The resources used to train the model can be repurposed to run millions of instances of it (this matches projected cluster sizes by ~2027), and the model can absorb information and generate actions at roughly 10x-100x human speed. It may however be limited by the response time of the physical world or of software it interacts with. Each of these million copies can act independently on unrelated tasks, or if needed can all work together in the same way humans would collaborate, perhaps with different subpopulations fine-tuned to be especially good at particular tasks.
In the post I'm quoting, Amodei is coy about the timeline for this stuff, saying only that
I think it could come as early as 2026, though there are also ways it could take much longer. But for the purposes of this essay, I’d like to put these issues aside [...]
However, other official communications from Anthropic have been more specific. Most notable is their recent OSTP submission, which states (emphasis in original):
Based on current research trajectories, we anticipate that powerful AI systems could emerge as soon as late 2026 or 2027 [...] Powerful AI technology will be built during this Administration. [i.e. the current Trump administration -nost]
See also here, where Jack Clark says (my emphasis):
People underrate how significant and fast-moving AI progress is. We have this notion that in late 2026, or early 2027, powerful AI systems will be built that will have intellectual capabilities that match or exceed Nobel Prize winners. They’ll have the ability to navigate all of the interfaces… [Clark goes on, mentioning some of the other tenets of "powerful AI" as in other Anthropic communications -nost]
----
To be clear, extremely short timelines like these are not unique to Anthropic.
Miles Brundage (ex-OpenAI) says something similar, albeit less specific, in this post. And Daniel Kokotajlo (also ex-OpenAI) has held views like this for a long time now.
Even Sam Altman himself has said similar things (though in much, much vaguer terms, both on the content of the deliverable and the timeline).
Still, Anthropic's statements are unique in being
official positions of the company
extremely specific and ambitious about the details
extremely aggressive about the timing, even by the standards of "short timelines" AI prognosticators in the same social cluster
Re: ambition, note that the definition of "powerful AI" seems almost the opposite of what you'd come up with if you were trying to make a confident forecast of something.
Often people will talk about "AI capable of transforming the world economy" or something more like that, leaving room for the AI in question to do that in one of several ways, or to do so while still failing at some important things.
But instead, Anthropic's definition is a big conjunctive list of "it'll be able to do this and that and this other thing and...", and each individual capability is defined in the most aggressive possible way, too! Not just "good enough at science to be extremely useful for scientists," but "smarter than a Nobel Prize winner," across "most relevant fields" (whatever that means). And not just good at science but also able to "write extremely good novels" (note that we have a long way to go on that front, and I get the feeling that people at AI labs don't appreciate the extent of the gap [cf]). Not only can it use a computer interface, it can use every computer interface; not only can it use them competently, but it can do so better than the best humans in the world. And all of that is in the first two paragraphs – there's four more paragraphs I haven't even touched in this little summary!
Re: timing, they have even shorter timelines than Kokotajlo these days, which is remarkable since he's historically been considered "the guy with the really short timelines." (See here where Kokotajlo states a median prediction of 2028 for "AGI," by which he means something less impressive than "powerful AI"; he expects something close to the "powerful AI" vision ["ASI"] ~1 year or so after "AGI" arrives.)
----
I, uh, really do not think this is going to happen in "late 2026 or 2027."
Or even by the end of this presidential administration, for that matter.
I can imagine it happening within my lifetime – which is wild and scary and marvelous. But in 1.5 years?!
The confusing thing is, I am very familiar with the kinds of arguments that "short timelines" people make, and I still find the Anthropic's timelines hard to fathom.
Above, I mentioned that Anthropic has shorter timelines than Daniel Kokotajlo, who "merely" expects the same sort of thing in 2029 or so. This probably seems like hairsplitting – from the perspective of your average person not in these circles, both of these predictions look basically identical, "absurdly good godlike sci-fi AI coming absurdly soon." What difference does an extra year or two make, right?
But it's salient to me, because I've been reading Kokotajlo for years now, and I feel like I basically get understand his case. And people, including me, tend to push back on him in the "no, that's too soon" direction. I've read many many blog posts and discussions over the years about this sort of thing, I feel like I should have a handle on what the short-timelines case is.
But even if you accept all the arguments evinced over the years by Daniel "Short Timelines" Kokotajlo, even if you grant all the premises he assumes and some people don't – that still doesn't get you all the way to the Anthropic timeline!
To give a very brief, very inadequate summary, the standard "short timelines argument" right now is like:
Over the next few years we will see a "growth spurt" in the amount of computing power ("compute") used for the largest LLM training runs. This factor of production has been largely stagnant since GPT-4 in 2023, for various reasons, but new clusters are getting built and the metaphorical car will get moving again soon. (See here)
By convention, each "GPT number" uses ~100x as much training compute as the last one. GPT-3 used ~100x as much as GPT-2, and GPT-4 used ~100x as much as GPT-3 (i.e. ~10,000x as much as GPT-2).
We are just now starting to see "~10x GPT-4 compute" models (like Grok 3 and GPT-4.5). In the next few years we will get to "~100x GPT-4 compute" models, and by 2030 will will reach ~10,000x GPT-4 compute.
If you think intuitively about "how much GPT-4 improved upon GPT-3 (100x less) or GPT-2 (10,000x less)," you can maybe convince yourself that these near-future models will be super-smart in ways that are difficult to precisely state/imagine from our vantage point. (GPT-4 was way smarter than GPT-2; it's hard to know what "projecting that forward" would mean, concretely, but it sure does sound like something pretty special)
Meanwhile, all kinds of (arguably) complementary research is going on, like allowing models to "think" for longer amounts of time, giving them GUI interfaces, etc.
All that being said, there's still a big intuitive gap between "ChatGPT, but it's much smarter under the hood" and anything like "powerful AI." But...
...the LLMs are getting good enough that they can write pretty good code, and they're getting better over time. And depending on how you interpret the evidence, you may be able to convince yourself that they're also swiftly getting better at other tasks involved in AI development, like "research engineering." So maybe you don't need to get all the way yourself, you just need to build an AI that's a good enough AI developer that it improves your AIs faster than you can, and then those AIs are even better developers, etc. etc. (People in this social cluster are really keen on the importance of exponential growth, which is generally a good trait to have but IMO it shades into "we need to kick off exponential growth and it'll somehow do the rest because it's all-powerful" in this case.)
And like, I have various disagreements with this picture.
For one thing, the "10x" models we're getting now don't seem especially impressive – there has been a lot of debate over this of course, but reportedly these models were disappointing to their own developers, who expected scaling to work wonders (using the kind of intuitive reasoning mentioned above) and got less than they hoped for.
And (in light of that) I think it's double-counting to talk about the wonders of scaling and then talk about reasoning, computer GUI use, etc. as complementary accelerating factors – those things are just table stakes at this point, the models are already maxing out the tasks you had defined previously, you've gotta give them something new to do or else they'll just sit there wasting GPUs when a smaller model would have sufficed.
And I think we're already at a point where nuances of UX and "character writing" and so forth are more of a limiting factor than intelligence. It's not a lack of "intelligence" that gives us superficially dazzling but vapid "eyeball kick" prose, or voice assistants that are deeply uncomfortable to actually talk to, or (I claim) "AI agents" that get stuck in loops and confuse themselves, or any of that.
We are still stuck in the "Helpful, Harmless, Honest Assistant" chatbot paradigm – no one has seriously broke with it since that Anthropic introduced it in a paper in 2021 – and now that paradigm is showing its limits. ("Reasoning" was strapped onto this paradigm in a simple and fairly awkward way, the new "reasoning" models are still chatbots like this, no one is actually doing anything else.) And instead of "okay, let's invent something better," the plan seems to be "let's just scale up these assistant chatbots and try to get them to self-improve, and they'll figure it out." I won't try to explain why in this post (IYI I kind of tried to here) but I really doubt these helpful/harmless guys can bootstrap their way into winning all the Nobel Prizes.
----
All that stuff I just said – that's where I differ from the usual "short timelines" people, from Kokotajlo and co.
But OK, let's say that for the sake of argument, I'm wrong and they're right. It still seems like a pretty tough squeeze to get to "powerful AI" on time, doesn't it?
In the OSTP submission, Anthropic presents their latest release as evidence of their authority to speak on the topic:
In February 2025, we released Claude 3.7 Sonnet, which is by many performance benchmarks the most powerful and capable commercially-available AI system in the world.
I've used Claude 3.7 Sonnet quite a bit. It is indeed really good, by the standards of these sorts of things!
But it is, of course, very very far from "powerful AI." So like, what is the fine-grained timeline even supposed to look like? When do the many, many milestones get crossed? If they're going to have "powerful AI" in early 2027, where exactly are they in mid-2026? At end-of-year 2025?
If I assume that absolutely everything goes splendidly well with no unexpected obstacles – and remember, we are talking about automating all human intellectual labor and all tasks done by humans on computers, but sure, whatever – then maybe we get the really impressive next-gen models later this year or early next year... and maybe they're suddenly good at all the stuff that has been tough for LLMs thus far (the "10x" models already released show little sign of this but sure, whatever)... and then we finally get into the self-improvement loop in earnest, and then... what?
They figure out to squeeze even more performance out of the GPUs? They think of really smart experiments to run on the cluster? Where are they going to get all the missing information about how to do every single job on earth, the tacit knowledge, the stuff that's not in any web scrape anywhere but locked up in human minds and inaccessible private data stores? Is an experiment designed by a helpful-chatbot AI going to finally crack the problem of giving chatbots the taste to "write extremely good novels," when that taste is precisely what "helpful-chatbot AIs" lack?
I guess the boring answer is that this is all just hype – tech CEO acts like tech CEO, news at 11. (But I don't feel like that can be the full story here, somehow.)
And the scary answer is that there's some secret Anthropic private info that makes this all more plausible. (But I doubt that too – cf. Brundage's claim that there are no more secrets like that now, the short-timelines cards are all on the table.)
It just does not make sense to me. And (as you can probably tell) I find it very frustrating that these guys are out there talking about how human thought will basically be obsolete in a few years, and pontificating about how to find new sources of meaning in life and stuff, without actually laying out an argument that their vision – which would be the common concern of all of us, if it were indeed on the horizon – is actually likely to occur on the timescale they propose.
It would be less frustrating if I were being asked to simply take it on faith, or explicitly on the basis of corporate secret knowledge. But no, the claim is not that, it's something more like "now, now, I know this must sound far-fetched to the layman, but if you really understand 'scaling laws' and 'exponential growth,' and you appreciate the way that pretraining will be scaled up soon, then it's simply obvious that –"
No! Fuck that! I've read the papers you're talking about, I know all the arguments you're handwaving-in-the-direction-of! It still doesn't add up!
280 notes
·
View notes
Text
Ok no, I have to get it out of my system, Conrad is bad at podcasting. And just recording anything in general.

The sound padding is doing absolutely nothing. Sure, they’ve got it slapped on the walls, but it’s off to the side. Not behind them. Not in front of them. Just... chilling. Which is useless. You want that padding facing the source of the sound so it can catch the waves before they start bouncing all over the place.
Since both Ruby and Conrad are facing forward with the padding off to the side, her voice is bouncing off the wall behind him and hitting his mic again a split second later. That would be making the audio sound muddy and hollow. Having the foam off to the side like that is like putting a bandage next to your cut and wondering why you’re still bleeding.
Right now, the foam is just there for vibes. Bad vibes.
And who told this man to record in a glass box? Glass is terrible for audio. Everything bounces. Nothing gets absorbed. It turns your voice into a pinball machine. You could have a thousand-dollar mic and it would still sound like you’re talking inside a fishbowl. Plus, that room looks like it’s in the middle of an office space? Why, Conrad, you amoeba-brained sycophant, would you record anything there ever?? The background noise alone would be hell on Earth to try to edit out.

Pop filter and foam windscreen (mic cover)??? Both are designed to reduce plosive sounds—like "p" and "b"—by dispersing the air before it hits the microphone diaphragm. While it’s not wrong to use both, it’s redundant unless you're outdoors or in a particularly plosive-heavy environment. Stacking them can even dull the audio a bit.
Your mic doesn’t need two hats. Calm down.

Not an audio note but a soft box light in the shot?? No. Just no. They should be behind the camera, pointing at you. Or at least off to the side, not pointing directly down the middle. And what really gets me? There are windows. Real, working windows with actual sunlight. And what did Conrad do? He covered them with that useless sound padding. So now it’s badly lit and echoey.
He blocked out free, natural light to keep in the bad sound.
"But what if the sun’s there right when he’s trying to record?" some might say. That’s why curtains exist. And the soft box would still be in a bad spot.

Also, his camera audio is peaking like crazy. Even if he's not using the camera mic for the final cut, it’s still useless to record it like this. You know that Xbox early Halo/COD mic sound? That’s what this would sound like.
This happens when the input gain is too high, causing the audio to clip. Basically, the mic can’t handle it and the sound gets distorted. Ideally, you want your audio levels to peak in the yellow zone, around -12 dB to -6 dB. Not constantly slamming into the red at 0 dB. That’s reserved for 13-year-old prepubescents cursing you out for ruining their kill streak. And that’s it.
On top of that, both the left and right channels on the camera audio look identical, meaning the audio’s been merged into a single mono track. Which isn’t wrong for speech, but it kills any sense of space or direction. For dynamic audio, especially in a two-person setup, you don’t want everything crammed into one lane. (OR they’re both just peaking at the same time continuously, even when they’re not talking, which means it’s picking up background noise at a level so loud it’s pushing the mic into clipping.)

And to make things worse, the little "LIVE" tag in the bottom corner implies this is a livestream. But there doesn’t seem to be any livestream software open on his laptop, so I’m assuming there’s either a second offscreen computer handling the stream, or it’s hooked up to broadcast natively.
Either way, unless those mics are also connected to the camera or that other computer, that peaky, crunchy camera audio is what people are actually hearing.

Finally... it really helps if you hit the record button. He’s just playing back audio. I think that’s more of a “show” thing, but still.
(look I got a fancy degree in this stuff and I have to use it somehow)
#as a sound designer this scene gave me a headache#Ok now back to my usual schedule of silly memes and text posts#also It's blurry so it's hard to tell#but I'm pretty sure that bitch using GarageBand to record his propaganda nonsense.#Like you can shell out for multiple hyper realistic Holywood quality costumes of a creature you saw once#but you can't afford Pro Tools? 🙄#Doctor Who#Doctor Who lucky day#lucky day#Doctor Who spoilers#15th doctor#fifteenth doctor#doctor who#doctor who spoilers#dw spoilers#spoilers#doctorwho#the doctor#dw s2 e4#sound design
317 notes
·
View notes
Text
Generative AI Is Bad For Your Creative Brain
In the wake of early announcing that their blog will no longer be posting fanfiction, I wanted to offer a different perspective than the ones I’ve been seeing in the argument against the use of AI in fandom spaces. Often, I’m seeing the arguments that the use of generative AI or Large Language Models (LLMs) make creative expression more accessible. Certainly, putting a prompt into a chat box and refining the output as desired is faster than writing a 5000 word fanfiction or learning to draw digitally or traditionally. But I would argue that the use of chat bots and generative AI actually limits - and ultimately reduces - one’s ability to enjoy creativity.
Creativity, defined by the Cambridge Advanced Learner’s Dictionary & Thesaurus, is the ability to produce or use original and unusual ideas. By definition, the use of generative AI discourages the brain from engaging with thoughts creatively. ChatGPT, character bots, and other generative AI products have to be trained on already existing text. In order to produce something “usable,” LLMs analyzes patterns within text to organize information into what the computer has been trained to identify as “desirable” outputs. These outputs are not always accurate due to the fact that computers don’t “think” the way that human brains do. They don’t create. They take the most common and refined data points and combine them according to predetermined templates to assemble a product. In the case of chat bots that are fed writing samples from authors, the product is not original - it’s a mishmash of the writings that were fed into the system.
Dialectical Behavioral Therapy (DBT) is a therapy modality developed by Marsha M. Linehan based on the understanding that growth comes when we accept that we are doing our best and we can work to better ourselves further. Within this modality, a few core concepts are explored, but for this argument I want to focus on Mindfulness and Emotion Regulation. Mindfulness, put simply, is awareness of the information our senses are telling us about the present moment. Emotion regulation is our ability to identify, understand, validate, and control our reaction to the emotions that result from changes in our environment. One of the skills taught within emotion regulation is Building Mastery - putting forth effort into an activity or skill in order to experience the pleasure that comes with seeing the fruits of your labor. These are by no means the only mechanisms of growth or skill development, however, I believe that mindfulness, emotion regulation, and building mastery are a large part of the core of creativity. When someone uses generative AI to imitate fanfiction, roleplay, fanart, etc., the core experience of creative expression is undermined.
Creating engages the body. As a writer who uses pen and paper as well as word processors while drafting, I had to learn how my body best engages with my process. The ideal pen and paper, the fact that I need glasses to work on my computer, the height of the table all factor into how I create. I don’t use audio recordings or transcriptions because that’s not a skill I’ve cultivated, but other authors use those tools as a way to assist their creative process. I can’t speak with any authority to the experience of visual artists, but my understanding is that the feedback and feel of their physical tools, the programs they use, and many other factors are not just part of how they learned their craft, they are essential to their art.
Generative AI invites users to bypass mindfully engaging with the physical act of creating. Part of becoming a person who creates from the vision in one’s head is the physical act of practicing. How did I learn to write? By sitting down and making myself write, over and over, word after word. I had to learn the rhythms of my body, and to listen when pain tells me to stop. I do not consider myself a visual artist - I have not put in the hours to learn to consistently combine line and color and form to show the world the idea in my head.
But I could.
Learning a new skill is possible. But one must be able to regulate one’s unpleasant emotions to be able to get there. The emotion that gets in the way of most people starting their creative journey is anxiety. Instead of a focus on “fear,” I like to define this emotion as “unpleasant anticipation.” In Atlas of the Heart, Brene Brown identifies anxiety as both a trait (a long term characteristic) and a state (a temporary condition). That is, we can be naturally predisposed to be impacted by anxiety, and experience unpleasant anticipation in response to an event. And the action drive associated with anxiety is to avoid the unpleasant stimulus.
Starting a new project, developing a new skill, and leaning into a creative endevor can inspire and cause people to react to anxiety. There is an unpleasant anticipation of things not turning out exactly correctly, of being judged negatively, of being unnoticed or even ignored. There is a lot less anxiety to be had in submitting a prompt to a machine than to look at a blank page and possibly make what could be a mistake. Unfortunately, the more something is avoided, the more anxiety is generated when it comes up again. Using generative AI doesn’t encourage starting a new project and learning a new skill - in fact, it makes the prospect more distressing to the mind, and encourages further avoidance of developing a personal creative process.
One of the best ways to reduce anxiety about a task, according to DBT, is for a person to do that task. Opposite action is a method of reducing the intensity of an emotion by going against its action urge. The action urge of anxiety is to avoid, and so opposite action encourages someone to approach the thing they are anxious about. This doesn’t mean that everyone who has anxiety about creating should make themselves write a 50k word fanfiction as their first project. But in order to reduce anxiety about dealing with a blank page, one must face and engage with a blank page. Even a single sentence fragment, two lines intersecting, an unintentional drop of ink means the page is no longer blank. If those are still difficult to approach a prompt, tutorial, or guided exercise can be used to reinforce the understanding that a blank page can be changed, slowly but surely by your own hand.
(As an aside, I would discourage the use of AI prompt generators - these often use prompts that were already created by a real person without credit. Prompt blogs and posts exist right here on tumblr, as well as imagines and headcannons that people often label “free to a good home.” These prompts can also often be specific to fandom, style, mood, etc., if you’re looking for something specific.)
In the current social media and content consumption culture, it’s easy to feel like the first attempt should be a perfect final product. But creating isn’t just about the final product. It’s about the process. Bo Burnam’s Inside is phenomenal, but I think the outtakes are just as important. We didn’t get That Funny Feeling and How the World Works and All Eyes on Me because Bo Burnham woke up and decided to write songs in the same day. We got them because he’s been been developing and honing his craft, as well as learning about himself as a person and artist, since he was a teenager. Building mastery in any skill takes time, and it’s often slow.
Slow is an important word, when it comes to creating. The fact that skill takes time to develop and a final piece of art takes time regardless of skill is it’s own source of anxiety. Compared to @sentientcave, who writes about 2k words per day, I’m very slow. And for all the time it takes me, my writing isn’t perfect - I find typos after posting and sometimes my phrasing is awkward. But my writing is better than it was, and my confidence is much higher. I can sit and write for longer and longer periods, my projects are more diverse, I’m sharing them with people, even before the final edits are done. And I only learned how to do this because I took the time to push through the discomfort of not being as fast or as skilled as I want to be in order to learn what works for me and what doesn’t.
Building mastery - getting better at a skill over time so that you can see your own progress - isn’t just about getting better. It’s about feeling better about your abilities. Confidence, excitement, and pride are important emotions to associate with our own actions. It teaches us that we are capable of making ourselves feel better by engaging with our creativity, a confidence that can be generalized to other activities.
Generative AI doesn’t encourage its users to try new things, to make mistakes, and to see what works. It doesn’t reward new accomplishments to encourage the building of new skills by connecting to old ones. The reward centers of the brain have nothing to respond to to associate with the action of the user. There is a short term input-reward pathway, but it’s only associated with using the AI prompter. It’s designed to encourage the user to come back over and over again, not develop the skill to think and create for themselves.
I don’t know that anyone will change their minds after reading this. It’s imperfect, and I’ve summarized concepts that can take months or years to learn. But I can say that I learned something from the process of writing it. I see some of the flaws, and I can see how my essay writing has changed over the years. This might have been faster to plug into AI as a prompt, but I can see how much more confidence I have in my own voice and opinions. And that’s not something chatGPT can ever replicate.
151 notes
·
View notes
Text
Disclaimer that this is a post mostly motivated by frustration at a cultural trend, not at any individual people/posters. Vagueing to avoid it seeming like a callout but I know how Tumblr is so we'll see I guess. Putting it after a read-more because I think it's going to spiral out of control.
Recent discourse around obnoxious Linux shills chiming in on posts about how difficult it can be to pick up computer literacy these days has made me feel old and tired. I get that people just want computers to Work and they don't want to have to put any extra effort into getting it to Do The Thing, that's not unreasonable, I want the same!
(I also want obnoxious Linux shills to not chip in on my posts (unless I am posting because my Linux has exploded and I need help) so I sympathise with that angle too, 'just use Linux' is not the catch-all solution you think it is my friend.)
But I keep seeing this broad sense of learned helplessness around having to learn about what the computer is actually doing without having your hand held by a massive faceless corporation, and I just feel like it isn't a healthy relationship to have with your tech.
The industry is getting worse and worse in their lack of respect to the consumer every quarter. Microsoft is comfortable pivoting their entire business to push AI on every part of their infrastructure and in every service, in part because their customers aren't going anywhere and won't push back in the numbers that might make a difference. Windows 11 has hidden even more functionality behind layers of streamlining and obfuscation and integrated even more spyware and telemetry that won't tell you shit about what it's doing and that you can't turn off without violating the EULA. They're going to keep pursuing this kind of shit in more and more obvious ways because that's all they can do in the quest for endless year on year growth.
Unfortunately, switching to Linux will force you to learn how to use it. That sucks when it's being pushed as an immediate solution to a specific problem you're having! Not going to deny that. FOSS folks need to realise that 'just pivot your entire day to day workflow to a new suite of tools designed by hobby engineers with really specific chips on their shoulders' does not work as a method of evangelism. But if you approach it more like learning to understand and control your tech, I think maybe it could be a bit more palatable? It's more like a set of techniques and strategies than learning a specific workflow. Once you pick up the basic patterns, you can apply them to the novel problems that inevitably crop up. It's still painful, particularly if you're messing around with audio or graphics drivers, but importantly, you are always the one in control. You might not know how to drive, and the engine might be on fire, but you're not locked in a burning Tesla.
Now that I write this it sounds more like a set of coping mechanisms, but to be honest I do not have a healthy relationship with xorg.conf and probably should seek therapy.
It's a bit of a stretch but I almost feel like a bit of friction with tech is necessary to develop a good relationship with it? Growing up on MS-DOS and earlier versions of Windows has given me a healthy suspicion of any time my computer does something without me telling it to, and if I can't then see what it did, something's very off. If I can't get at the setting and properties panel for something, my immediate inclination is to uninstall it and do without.
And like yeah as a final note, I too find it frustrating when Linux decides to shit itself and the latest relevant thread I can find on the matter is from 2006 and every participant has been Raptured since, but at least threads exist. At least they're not Microsoft Community hellscapes where every second response is a sales rep telling them to open a support ticket. At least there's some transparency and openness around how the operating system is made and how it works. At least you have alternatives if one doesn't do the job for you.
This is long and meandering and probably misses the point of the discourse I'm dragging but I felt obligated to make it. Ubuntu Noble Numbat is pretty good and I haven't had any issues with it out of the box (compared to EndeavourOS becoming a hellscape whenever I wanted my computer to make a sound or render a graphic) so I recommend it. Yay FOSS.

219 notes
·
View notes